在當今這個信息爆炸的時代,大數據已經滲透到我們生活的方方面面,從商業決策、醫療健康到城市規劃、科學研究,無處不在。海量的原始數據本身價值有限,只有經過精心的“加工”——即數據處理——才能轉化為真正有用的信息、知識和洞見。本文將帶您走進數據處理的世界,一探其究竟。
一、什么是數據處理?
數據處理是指對收集到的原始數據進行一系列操作,包括清洗、轉換、整合、分析和可視化等,其目標是將其轉化為結構化的、易于理解和使用的格式,以支持決策、發現規律或驅動智能應用。它是連接原始數據與最終價值的橋梁,是整個大數據價值鏈中最核心的環節之一。
二、數據處理的關鍵步驟
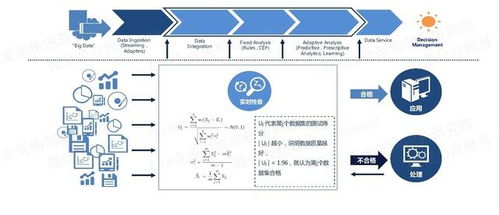
一個完整的數據處理流程通常包含以下幾個核心階段:
- 數據采集與集成:從各種來源(如傳感器、日志文件、數據庫、社交媒體)收集原始數據,并將其匯集到一起。
- 數據清洗與預處理:這是至關重要的一步,旨在處理“臟數據”,如糾正錯誤、填補缺失值、消除重復、統一格式、處理異常值等,確保數據的質量和一致性。
- 數據存儲與管理:將清洗后的數據高效、可靠地存儲起來,可能涉及分布式文件系統(如HDFS)、NoSQL數據庫(如HBase、MongoDB)或數據倉庫等技術。
- 數據轉換與計算:根據分析目標,對數據進行聚合、過濾、關聯、計算衍生指標等操作。這一過程可能涉及批處理(如使用MapReduce、Spark處理歷史數據)或流處理(如使用Flink、Storm處理實時數據流)。
- 數據分析與挖掘:運用統計分析、機器學習、深度學習等算法,從數據中發現模式、趨勢、關聯和預測未來。
- 數據可視化與呈現:將分析結果以圖表、儀表盤等直觀形式展現出來,使非技術人員也能輕松理解數據背后的故事。
三、核心技術框架與工具
為應對大數據處理的挑戰(體量大、速度快、類型多、價值密度低),一系列強大的技術棧應運而生:
- 批處理框架:如Apache Hadoop(MapReduce)和Apache Spark,擅長處理海量的、靜態的歷史數據集,進行復雜的批量計算。
- 流處理框架:如Apache Flink、Apache Storm和Spark Streaming,能夠對連續不斷產生的數據流進行實時或近實時的處理和分析。
- 數據處理引擎/查詢引擎:如Apache Hive、Presto、Impala,提供了類SQL的接口,方便分析師對大規模數據進行查詢和分析。
- 資源管理與協調框架:如Apache YARN和Kubernetes,負責管理和調度集群的計算資源。
四、數據處理的應用價值
高效的數據處理能力是解鎖大數據價值的關鍵。它使得:
- 企業智能決策:通過分析銷售、用戶行為等數據,優化產品、營銷和運營策略。
- 個性化服務:例如,電商平臺的推薦系統、新聞資訊的個性化推送,都依賴于對用戶數據的實時處理。
- 風險管控與預測:金融領域的欺詐檢測、信用評估,工業領域的設備預測性維護,都離不開對海量數據的快速處理與分析。
- 科學研究突破:在天文、生物信息學等領域,處理PB級的數據已成為常態,推動了重大科學發現。
五、未來趨勢與挑戰
隨著數據量的持續增長和技術的不斷演進,數據處理領域也在快速發展:
- 實時化與智能化:對數據處理速度的要求越來越高,實時流處理與AI/ML的結合日益緊密。
- 湖倉一體與數據編織:打破數據湖與數據倉庫的界限,構建更靈活、統一的數據架構,簡化數據管理和處理流程。
- 自動化與低代碼/無代碼:自動化數據管道構建、數據質量監控,以及面向業務人員的低代碼數據分析工具,正降低數據處理的門檻。
- 隱私與安全:在數據處理全過程中,如何保護個人隱私和數據安全,是必須面對的嚴峻挑戰。
數據處理是大數據生態系統的引擎。理解并掌握數據處理的技術與流程,意味著掌握了從數據金礦中提煉真金的能力。它不僅是技術專家的領域,也逐漸成為每一位希望從數據中獲益的現代人所應具備的基本素養。